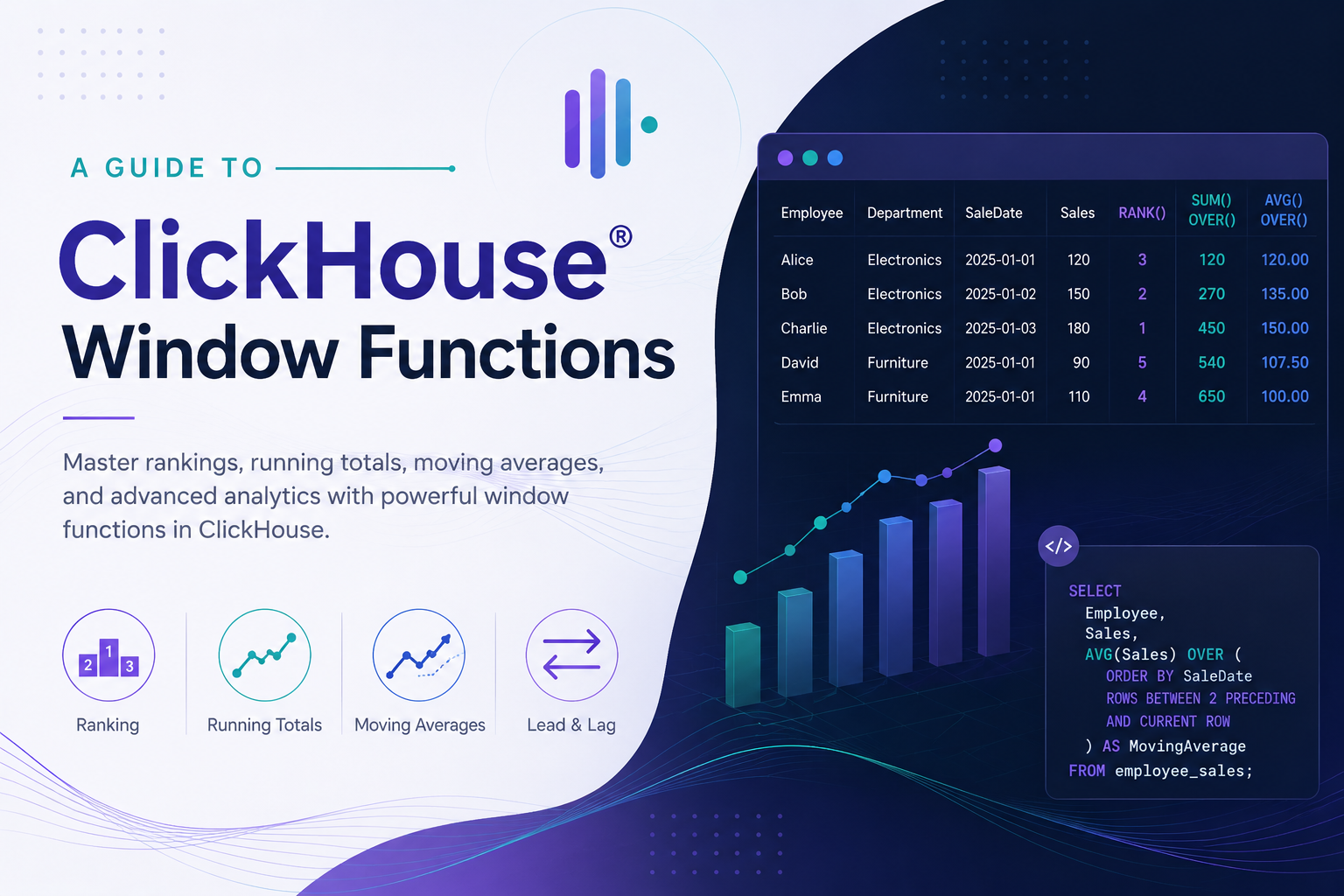
Introduction
Missing or incomplete data is a common challenge in analytical databases. Whether data is unavailable, unknown, or intentionally omitted, handling these values correctly is essential for producing accurate query results and maintaining efficient data models.
ClickHouse® provides several features for managing missing data, including the Nullable data type, default values, and built-in functions for working with NULL values. Choosing the right approach helps improve query accuracy while minimizing unnecessary storage and processing overhead.
In this article, we'll explore how ClickHouse handles NULL values, understand the differences between NULL and default values, and learn practical techniques and best practices for working with missing data.
1. Understanding NULL and Missing Data
Although they are often used interchangeably, NULL values, missing data, and default values represent different concepts.
- NULL represents an unknown or unavailable value.
- Missing data occurs when a value is omitted during insertion.
- Default values are automatically assigned when no value is provided for a column.
For example:
| Customer | Coupon Code |
|---|---|
| Alice | SAVE10 |
| Bob | NULL |
In this example, NULL indicates that Bob's coupon code is unknown or unavailable. It is different from an empty string ('') or a default value.
Understanding these differences helps ensure accurate data modeling and reporting.
2. When Should You Use NULL Values?
NULL values are useful when the absence of data has business meaning. Common scenarios include:
- Optional customer information such as phone numbers or email addresses.
- IoT devices that occasionally miss sensor readings.
- Financial transactions with optional discount or referral codes.
- Application logs containing optional metadata.
- Healthcare datasets with unavailable measurements.
If the missing value represents an unknown or unavailable state, using NULL is generally more appropriate than storing a default value.
3. Using the Nullable Data Type
By default, ClickHouse columns cannot store NULL values. To allow missing values, wrap the data type using Nullable().
CREATE TABLE employees
(
id UInt32,
name String,
email Nullable(String)
)
ENGINE = MergeTree
ORDER BY id;Now inserting NULL values is valid.
INSERT INTO employees VALUES
(1,'Alice','alice@example.com'),
(2,'Bob',NULL);Using Nullable() allows ClickHouse to distinguish between actual values and missing information.
4. Querying NULL Values
Use IS NULL and IS NOT NULL to filter nullable columns.
Find rows with NULL values
SELECT *
FROM employees
WHERE email IS NULL;Find rows with valid values
SELECT *
FROM employees
WHERE email IS NOT NULL;Note: Avoid comparing NULL values using
=or!=, as these operators do not work for NULL comparisons.
5. Useful Functions for Handling NULL Values
ClickHouse includes several built-in functions for working with nullable data.
ifNull()
Returns a replacement value when the expression is NULL.
SELECT
customer_name,
ifNull(email, 'Not Available') AS email
FROM employees;coalesce()
Returns the first non-NULL value from multiple expressions.
SELECT
customer_name,
coalesce(work_email, personal_email, 'Unknown') AS contact
FROM employees;This is useful when multiple columns can contain the desired value.
nullIf()
Returns NULL when two expressions are equal.
SELECT
nullIf(score, 0);This function is commonly used to convert placeholder values into NULL.
isNull()
Checks whether a value is NULL.
SELECT
isNull(email);Returns:
1if the value is NULL0otherwise
firstNonDefault()
Returns the first value that is not the default value.
SELECT
firstNonDefault('', 'Support', 'Admin');Output:
SupportThis is useful when working with default values instead of NULL.
6. NULL Values and Aggregate Functions
Most aggregate functions automatically ignore NULL values.
SELECT
avg(score)
FROM marks;Similarly,
SELECT
sum(score)
FROM marks;The following functions automatically ignore NULL values:
SUM()AVG()MIN()MAX()COUNT(column)
Whereas:
SELECT COUNT(*)
FROM marks;counts every row regardless of NULL values.
Understanding this behavior helps produce accurate analytical results.
7. Sorting NULL Values
NULL values are handled separately during sorting.
SELECT *
FROM employees
ORDER BY salary;Depending on the sorting settings, NULL values typically appear before or after non-NULL values.
8. Using assumeNotNull()
If you're certain a nullable column contains valid values, you can convert it into a non-nullable value.
SELECT
assumeNotNull(email)
FROM employees;This avoids nullable processing during query execution.
Note: Use
assumeNotNull()only when you're certain the value is not NULL. Calling it on NULL values may produce unexpected results.
9. When to Avoid Nullable Columns
Although nullable columns are useful, they introduce additional storage and processing overhead.
ClickHouse maintains an additional bitmap to indicate whether each value is NULL. While this overhead is generally small, excessive use of nullable columns can increase storage usage and introduce extra checks during query execution.
Whenever appropriate, consider using:
- Empty strings
- Zero values
- Default timestamps
- Business-specific default values
instead of NULL.
For example, instead of storing:
NULLconsider storing:
Unknownwhen it accurately represents the business requirement.
10. Common Use Cases
Handling NULL values is common in many analytical workloads, including:
- Customer profiles with optional contact information
- IoT sensor readings with intermittent data
- Application logs containing optional fields
- Event tracking pipelines
- Financial transactions with incomplete metadata
- Healthcare datasets with unavailable measurements
11. Example Data Cleaning Workflow
Suppose an analytics dashboard requires customer contact information.
A typical workflow could be:
- Identify customers with missing email addresses.
- Use phone numbers when email is unavailable.
- Replace remaining missing values with a default label.
- Generate reports without excluding incomplete records.
Example:
SELECT
customer_name,
coalesce(email, phone, 'No Contact Available') AS contact
FROM customer_orders;This ensures every customer record contains a meaningful contact value for reporting.
12. Common Pitfalls
When working with NULL values, keep the following in mind:
- Don't compare NULL values using
=or!=. - Avoid making every column nullable.
- Don't use nullable columns in primary or sorting keys unless necessary.
- Understand how aggregate functions treat NULL values before building reports.
- Use meaningful default values only when they accurately represent the business requirement.
Avoiding these mistakes results in cleaner schemas and more efficient queries.
13. Best Practices
To manage missing data efficiently in ClickHouse:
- Use
Nullable()only when missing information has business significance. - Prefer default values whenever appropriate.
- Use
ifNull()for simple replacements. - Use
coalesce()when multiple fallback values exist. - Filter NULL values using
IS NULLandIS NOT NULL. - Understand how aggregate functions treat NULL values.
- Avoid unnecessary nullable columns in high-performance tables.
- Clean and validate data before ingestion whenever possible.
- Document how NULL values are interpreted across your datasets.
Following these practices improves both data quality and query performance.
Conclusion
Handling missing data correctly is essential for building reliable analytical applications. ClickHouse® provides flexible support through the Nullable data type, built-in NULL functions, and default values, allowing developers to manage incomplete data efficiently.
By understanding when to use NULL values, choosing appropriate default values, and following best practices, you can build cleaner schemas, improve query accuracy, and maintain the high-performance analytics that ClickHouse is known for.