
When you are given a problem , it is customary to think like a tech savvy and solve it in a large scale for millions of users at first glance , but that would require time at hand , unfortunately time is currency in this modern world !….
We had a similar problem at hand , going to production quick and developers need to do trail and error to arrive at a model that is fitting for the real world data , eventhough approach would be to take a training dataset and make a model and promote to production , but we had the notion of testing the model in real world as prediction instead of validation to avoid biases – some human biases too
For the task at hand , we thought of introducing Kafka + Python + Spark for prediction , but this seems to be come with lot of challenges , main challenge is to make the data cleaning similar so developers just drop in model and verify prediction , but as we are still in phase of exploring dataset this is not a possiblity , so developer needs to make sure the code always ported to python script from notebooks , thought it is doable but is a additional overhead in the trail and error phase….
Here’s what we found from our discussion with developers and architects , that !!
“””Why build a tank for grocery shopping when you can just use bike””””.
The Temptation of the Big Stack
for the processes like running a daily report, transforming a dataset, or retraining a model — the reflex is often to spin up:
- Airflow or Prefect for orchestration
- Dockerized workers for execution
- Message queues for triggering and scaling
- Cloud pipelines for integration
These are powerful tools. But they come with:
- Operational overhead
- Infrastructure complexity
- Onboarding time for new team members
- More moving parts to fail
For our scope of the problem this seems like a overkill .
The Case for Going Simple
Our only goal is :
“Run a notebook every day at midnight, update some numbers, and save the result.”
That’s it. No dynamic scaling, no 50-step DAG, no event-driven microservice chain.
<< here is what we landed on after discussions >>
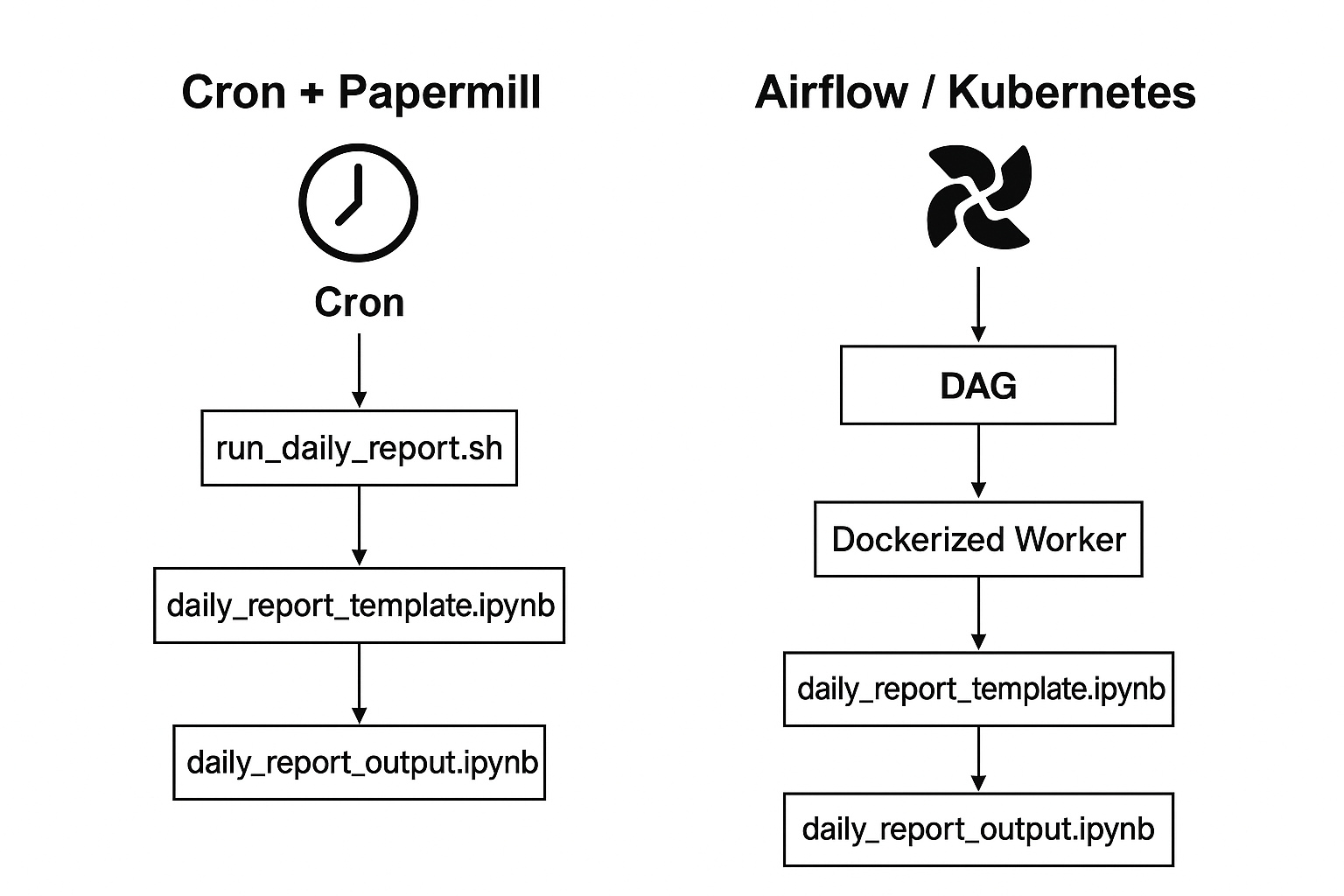
Cron :
“Decade old proven system with simpler enough configuration which each developer can even schedule it”
Example:
0 0 * * * /usr/local/bin/run_daily_report.sh
Papermill
- A tool for parameterizing and executing Jupyter notebooks
- Lets you treat notebooks as reproducible, automated scripts
- Can store both code and documentation together
- Works well for data science workflows without converting everything into pure Python scripts
Example:
papermill daily_report_template.ipynb daily_report_output.ipynb -p date "$(date +%F)"
In a nutshell
Benefits of the Simple Path
- Speed: You can set this up in hours, not days or weeks.
- Clarity: The workflow is transparent and easy to debug.
- Cost efficiency: No extra cloud services or always-on infrastructure.
- Maintainability: New developers can read the cron entry and the notebook — that’s the entire codebase.
When to Avoid Over-Simplification
Of course, this approach is not for everything.
If you have:
- Large-scale distributed data processing
- Complex dependencies between multiple tasks
- The need for retries, monitoring dashboards, or event-driven triggers
- Multi-team ownership and collaboration on orchestration
…then a more robust scheduler or orchestration platform might be worth it.
But for the 80% of internal, low-complexity jobs that companies run daily, this minimal approach can save time and money.
The Philosophy
In software, complexity has a cost.
Before pulling in the “big guns” of modern architecture, ask:
- What’s the smallest set of tools that solves the problem?
- Can we make it run without introducing another dependency?
- Will someone else be able to maintain this six months from now?
Sometimes, the humble cron job and a parameterized notebook are not just good enough — they’re the smartest choice.