Introduction
For businesses that rely on uninterrupted data access, minimizing downtime is a top priority. Ensuring high availability means implementing solutions that eliminate single points of failure and keep critical databases running smoothly.
While achieving 100% uptime is impossible, the industry standard for many businesses is 99.99% availability, or four-nines availability, which allows for less than an hour of downtime per year. This level of reliability helps prevent disruptions, protect revenue, and maintain customer confidence.
In an increasingly digital world, high availability isn’t just a technical goal - it’s a business imperative. Organizations that prioritize HA solutions strengthen resilience, improve user experience, and set themselves apart from the competition.
Determine your High Availability (HA) need
Database availability requirements vary depending on the industry and use case. For example, telecom databases often target 99.99% availability (four nines), which limits downtime to less than an hour per year. In contrast, less critical databases may operate at 99% availability (two nines), resulting in nearly four days of downtime annually.
Several factors influence high availability choices, including the number of impacted users, database size, and the total number of databases involved. Evaluating these factors is crucial for defining Recovery Time Objectives (RTO) and Recovery Point Objectives (RPO), both of which shape the system’s resilience and disaster recovery strategy.
RTO
Recovery Time Objective (RTO) defines the maximum acceptable downtime for both planned and unplanned outages. A lower RTO ensures faster recovery, minimizing operational disruptions.
OLTP databases - which power real-time applications like banking and e-commerce - require the lowest RTOs due to their critical nature. Even brief downtime can lead to financial losses and degraded user experiences. While scheduled maintenance for hardware and software is necessary, organizations must also plan for unplanned outages, as unexpected failures can severely impact business continuity.
RPO
Recovery Point Objective (RPO) defines the maximum acceptable data loss in the event of a failure. It plays a crucial role in high availability by determining how frequently data needs to be backed up or replicated.
For Online Analytical Processing (OLAP) environments, where data is typically processed in bulk once a day, an RPO of up to 24 hours may be sufficient. In contrast, Online Transaction Processing (OLTP) databases - such as those used in trading platforms and real-time web applications - require an RPO as close to zero as possible to prevent data loss and ensure seamless operations.
For seamless failover and disaster recovery, a synchronous database setup plays a vital role. Replicating data synchronously over a local area network (LAN) ensures real-time consistency, making it the ideal approach for critical systems with stringent RTO and RPO requirements.
However, when data spans geographically distributed data centers (WANs), asynchronous replication becomes necessary. This approach balances high throughput with efficiency, preventing performance bottlenecks while maintaining data integrity.
Investing in the right replication strategy isn’t optional - it’s essential. Allocating the necessary resources ensures businesses can meet high availability demands, minimize downtime, and maintain operational resilience.
High Availability (HA) in ClickHouse
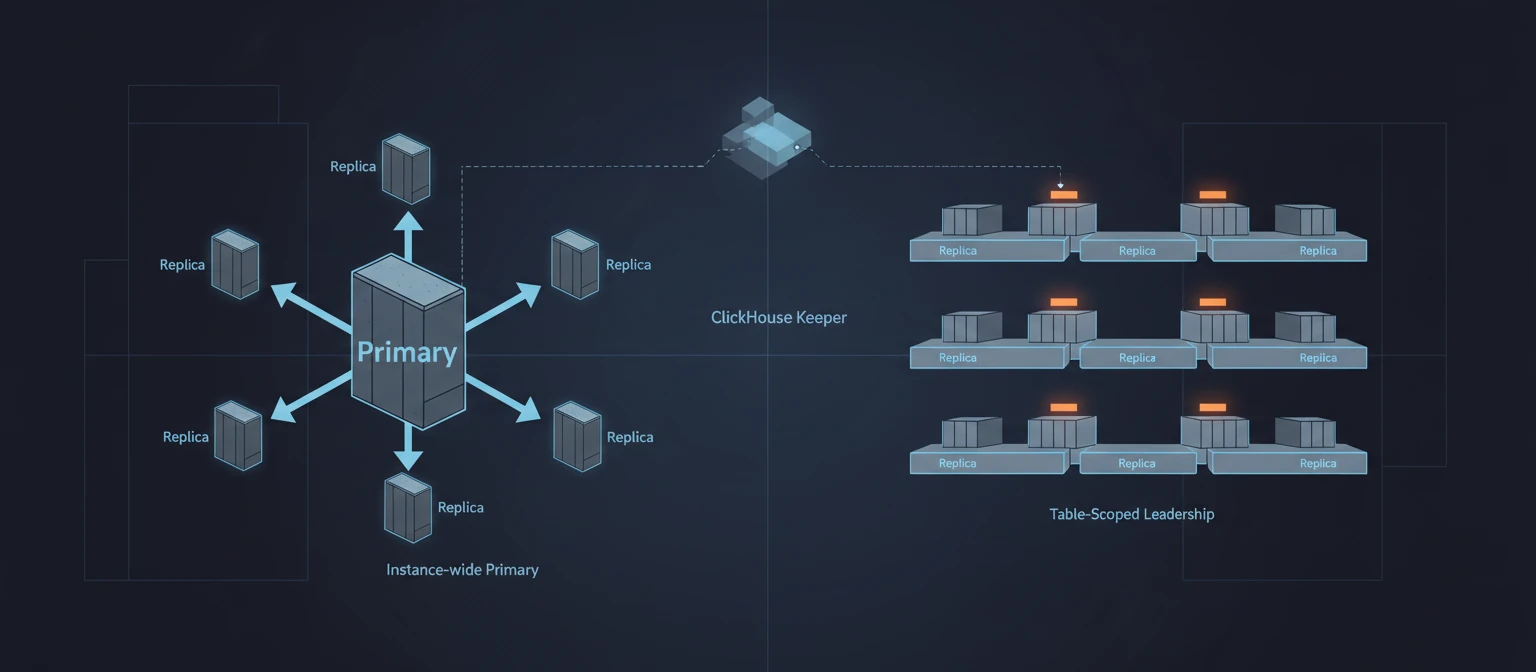
ClickHouse ensures high availability (HA) through its multi-leader, eventually consistent architecture, enabling fault tolerance and seamless failover. However, for effective coordination, ClickHouse requires either ZooKeeper or ClickHouse Keeper to manage replication and cluster state.
Key HA Components in ClickHouse
- Multi-Leader Replication
- ClickHouse supports multi-leader (active-active) replication, allowing multiple nodes to handle writes while maintaining eventual consistency.
- ReplicatedMergeTree tables enable automatic data synchronization across replicas.
- ZooKeeper or ClickHouse Keeper for Coordination
- ZooKeeper (or its native alternative, ClickHouse Keeper) is essential for:
- Replica Coordination – Ensuring proper synchronization and failover.
- Leader Election – Managing active replicas.
- Metadata Consistency – Avoiding conflicts between nodes.
- ZooKeeper (or its native alternative, ClickHouse Keeper) is essential for:
- Eventual Consistency Model
- Unlike traditional databases that enforce strict consistency, ClickHouse ensures all replicas eventually reach the same state.
- This trade-off allows for higher performance and scalability while maintaining availability.
- Sharding & Distributed Queries
- Distributed tables allow queries to span multiple nodes, balancing the workload and improving HA.
- Sharded architectures prevent a single point of failure and enable horizontal scaling.
- Failover & Self-Healing
- When a node fails, the system reroutes queries to available replicas.
- Mutation logs and background merges help ClickHouse recover data consistency after failures.
- Asynchronous Replication for Disaster Recovery
- When deploying across geographically separated data centers (WANs), asynchronous replication ensures high throughput while maintaining resilience.
Considerations for High Availability in ClickHouse
- ZooKeeper or ClickHouse Keeper is mandatory for replication and failover.
- Write conflicts may occur in multi-leader setups, requiring application-level conflict resolution.
- Replication topology and shard placement impact HA performance and recovery speed.
- Tuning required for query freshness, as eventual consistency might introduce slight delays.
Is ClickHouse the Right HA Solution for You?
ClickHouse’s HA model is well-suited for analytical workloads, offering fault tolerance, scalability, and distributed processing. However, applications needing strict ACID compliance may require alternative solutions.
Conclusion
ClickHouse delivers a high-availability architecture designed for scalability, performance, and fault tolerance, but achieving optimal resilience requires the right replication strategy, coordination with ZooKeeper or ClickHouse Keeper, and failover planning. While its multi-leader, eventually consistent model is well-suited for analytical workloads, businesses must fine-tune their setup to balance performance, consistency, and reliability.
At Quantrail, we simplify high availability for ClickHouse with a fully managed analytics platform that offers automated replication, seamless scaling, and built-in failover mechanisms. Our solution ensures maximum uptime, reduced complexity, and cost efficiency, enabling businesses to focus on insights instead of infrastructure.
📩 Contact us today to learn how Quantrail can enhance your ClickHouse deployment and drive your analytics performance forward.
https://quantrail-data.com/contact/
References
https://docs.altinity.com/operationsguide/availability-and-recovery/availability-architecture
https://chistadata.com/high-availability-replication-clickhouse
Image courtesy: Photo by Irita Antonevica: https://www.pexels.com/photo/close-up-of-strawberries-306800/